给女朋友写的一个简书爬虫
背景:女票参加了一个简书的写作训练营,并担任某个小班的班长,每个周末需要统计每个学员上一周写了多少篇文章以及写了哪些文章等数据。为了讨女票开心,于是就答应给她写一个简书的爬虫,用于统计数据,毕竟咋是搞这行的,能用程序解决的就坚决就不去做那种重复的体力活。
下面,咋一起来进入这个爬虫的书写
一、前期分析:
首先我们来分析一下我们要怎么爬,如图所示:
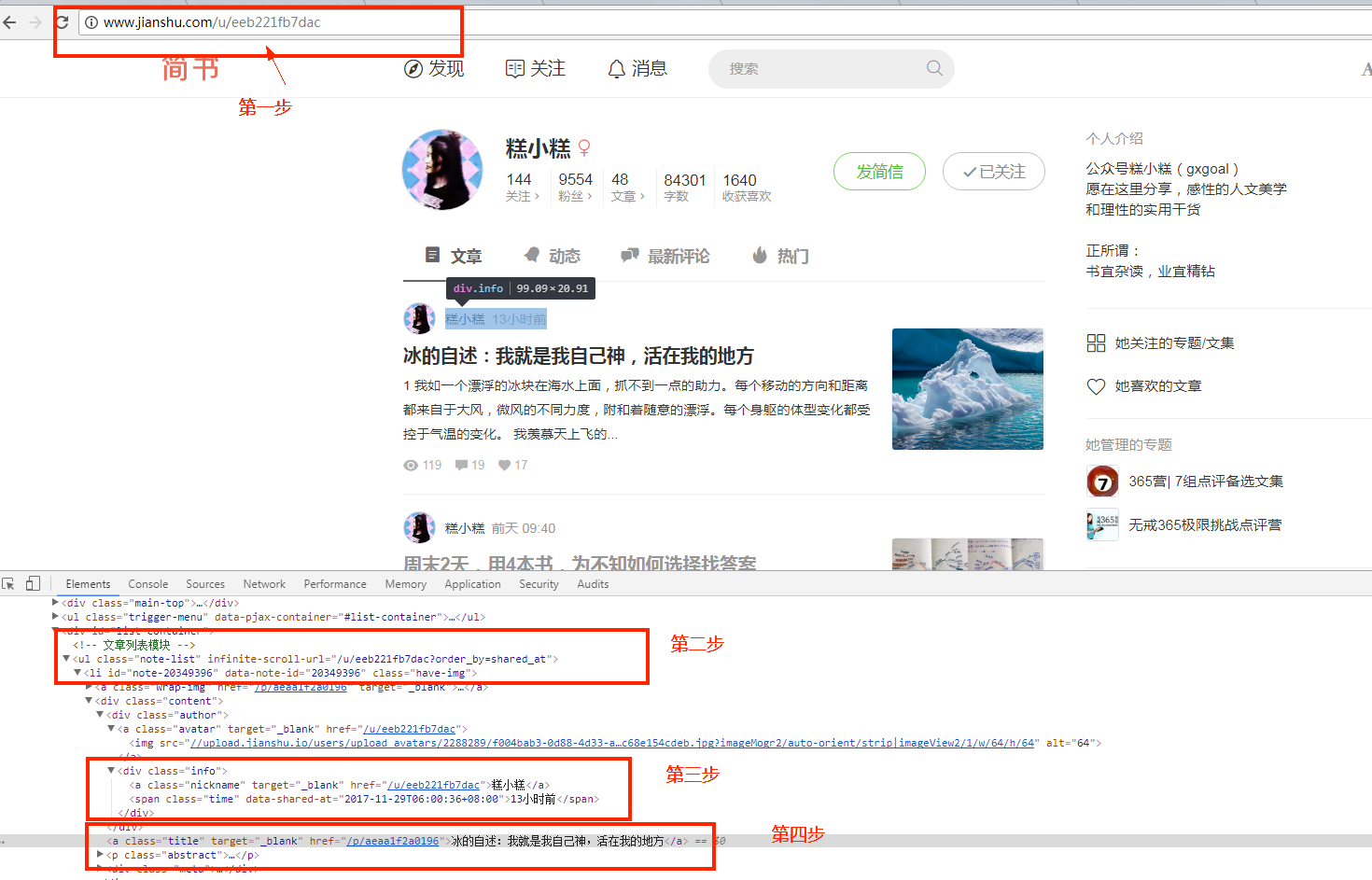
第一步:
我们需要进入到每个学员的用户中心,类似于这种链接: http://www.jianshu.com/u/eeb221fb7dac
这个只能由女票帮我们收集好她们班每个学员的用户中心的链接。有了这种用户中心的链接后,我们第一步要爬的就是这个用户中心
第二步:
爬取用户中心,我们需要获取到某些数据。如:我们统计的是上一周数据,所以需要某个时间段内,文章详情的链接集合、 用户名。
这些数据如何获取呢?如上图所示: 获取用户名,我们需要 $('.nickname') 这里的文本即可。获取某个时间段的文章详情链接,我们需要遍历 $('.note-list li')中的 $('.time') 和 $('.titile')
第三步:
爬取第二步获取到的文章详情链接,爬取文章详情里面的内容,文章详情类似的链接为: http://www.jianshu.com/p/aeaa1f2a0196
在文章详情页中,获取我们需要的数据,如: 标题,字数,阅读数等等。 如下图所示
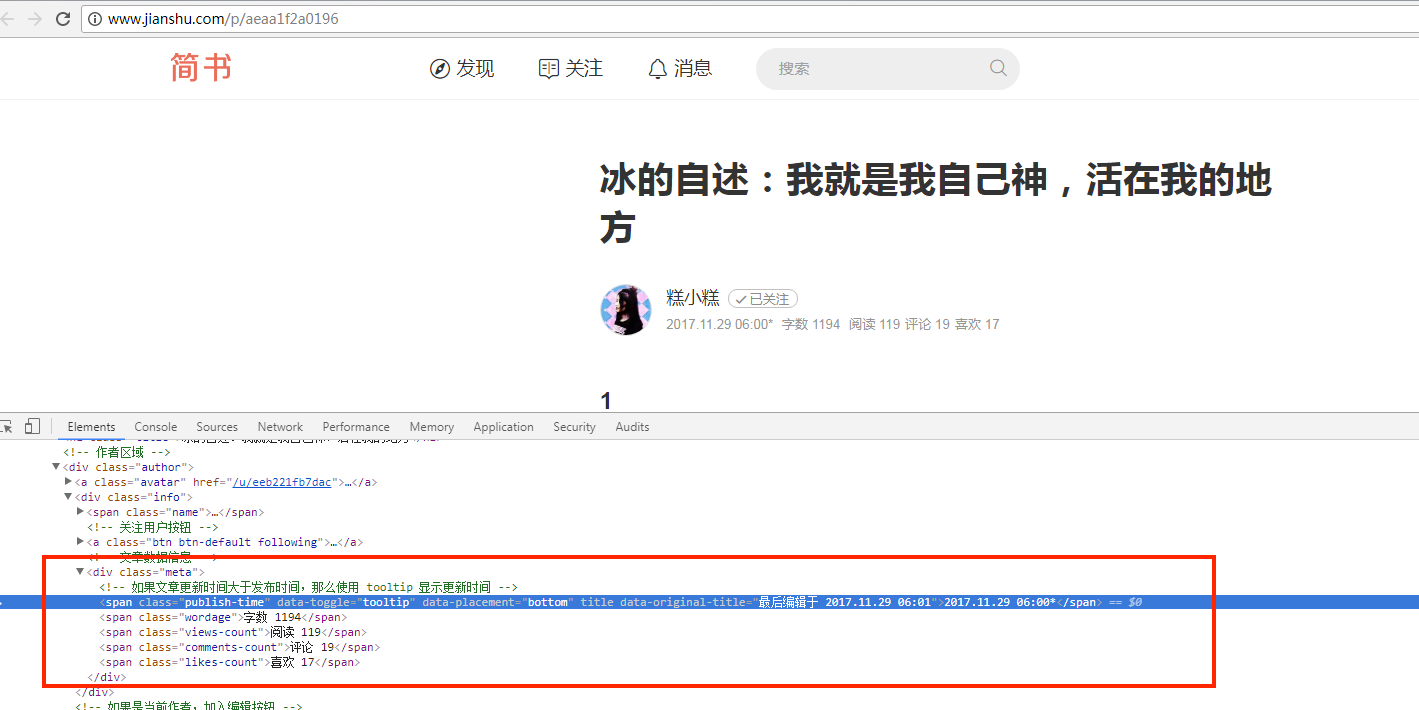
第四步:
将获取的数据生成excel表,这样女票才会更加的崇拜你,哇,斯国一。
二、前期准备:
经常上面的分析,下面我们来准备爬虫需要的工具:
cheerio: 让你可以像使用jquery一样操作爬取回来的页面superagent-charset: 解决爬回来的页面编码问题superagent: 用于发起请求async: 用于异步流程和并发控制ejsexcel: 用于生成excel表格express、node >=6.0.0这些模块具体用法,可以在这里查,https://www.npmjs.com ,一些用法下面会说到
三、开始爬虫
1.我们将所有学员的简书用户中心链接放在配置文件 config.js中,并定义了生成的excel表存放路径:
1 | const path = require('path'); |
由于要保护别人的信息,所以你可以去简书随便找其他人的用户中心,造更多的数据
2.我们先定义一些全局变量,如: 基础的链接,当前并发数,抓取错误的链接集合
1
2
3let _baseUrl = "http://www.jianshu.com",
_currentCount = 0,
_errorUrls = [];
3.封装一些函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// 封装 superagent 函数
const fetchUrl = (url,callback) => {
let fetchStart = new Date().getTime();
superagent
.get(url)
.charset('utf-8')
.end((err, ssres) => {
if(err) {
_errorUrls.push(url);
console.log('抓取【'+ url +'】出错');
return false;
}
let spendTime = new Date().getTime() - fetchStart;
console.log('抓取:'+ url +'成功,耗时:'+ spendTime +'毫秒,现在并发数为:'+ _currentCount );
_currentCount--;
callback(ssres.text);
});
}
// 数组去重
const removeSame = (arr) => {
const newArr = [];
const obj = {};
arr.forEach((item) => {
if(!obj[item.title]) {
newArr.push(item);
obj[item.title] = item.title;
}
});
return newArr;
}
4.开始爬取用户中心,获取某个时间段的文章详情链接
1 | // 爬取用户中心,获取某个时间段文章详情链接 |
在这里,用户中心的链接来自于 confg文件,我们使用 async.mapLimit来对我们的抓取做了一个并发控制,并发数最大为5。
async.mapLimit用法为: mapLimit(arr, limit, iterator, callback);
arr: 数组
limit: 并发数
iterator: 迭代器(处理函数), 这里指爬取一次用户中心,它里面 callback必须执行 ,将本次执行结果存储起来。
callback: 执行完成之后的回调。 所有的用户中心抓取完,抓取到的总结果返回这个回调里面。
从用户中心获取某个时间段的文章详情集合:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 获取某个时间段文章链接集合
const getDetailUrlCollections = ($,startTime,endTime) => {
let articleList = $('#list-container .note-list li'),
detailUrlCollections = [];
for(let i = 0,len = articleList.length; i < len; i++) {
let crateAt = articleList.eq(i).find('.author .time').attr('data-shared-at');
let createTime = new Date(crateAt).getTime();
if(createTime >= startTime && createTime <= endTime) {
let articleUrl = articleList.eq(i).find('.title').attr('href');
let url = _baseUrl + articleUrl;
detailUrlCollections.push(url);
}
}
return detailUrlCollections;
}
5.从第4步中,我们获取到了所有的文章详情链接,所以,下面我们来爬取文章详情里面的内容,做法跟第4步差不多
1 | // 爬取文章详情 |
从文章详情里,我们获取了标题,字数,发布时间,当然,你可以获取该页面你想要的信息,我这里不需要太多,这些就够了。这里获取到的数据是有重复的,所以要做数组去重处理
6.至此,我们需要爬取的数据都获取到了,最后一步,我们将其生成excel表格
用node生成excel表,找了一圈,发觉 ejsexcel 这个框架评价比较好。点击查看;
它的使用方法为: 我们先需要有一个excel表模板,然后在改模板里面,可以使用ejs语法,来按照我们的意思生成表格
1
2
3
4
5
6
7
8
9
10
11
12
13
14// 生成excel表
const createExcel = (dataArr,sumUpData) => {
const exlBuf = fs.readFileSync(config.excelFile.path + "/report.xlsx");
//数据源
const data = [ [{"table_name":"7班简书统计表","date": formatTime()}], dataArr, sumUpData ];
//用数据源(对象)data渲染Excel模板
ejsExcel.renderExcel(exlBuf, data)
.then(function(exlBuf2) {
fs.writeFileSync(config.excelFile.path + "/report2.xlsx", exlBuf2);
console.log("生成excel表成功");
}).catch(function(err) {
console.error('生成excel表失败');
});
}
先读取我们的模板,然后再将我们的数据写入到模板中,生成新的excel表格

7.由于抓取的时间是不固定的,所以我们将整个抓取的过程弄成由前端ajax请求的形式,传递 startTime 和 endTime这两个数据,前端界面比较简单

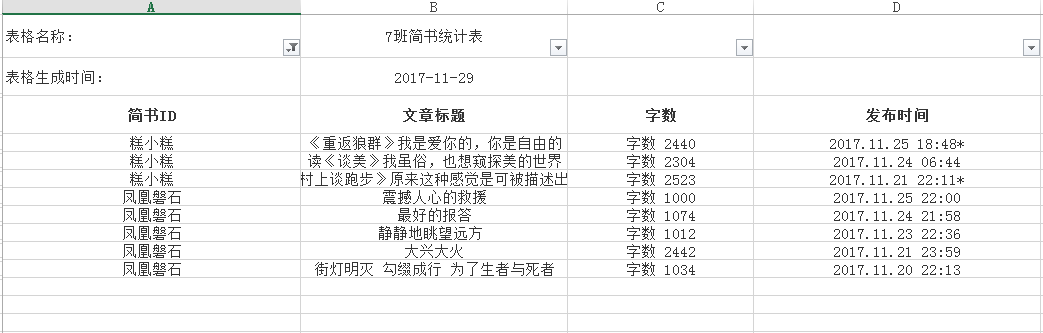
生成的excel表格图:
抓取的过程如下:
至此,我们的简书爬虫完成了,比较简单。
注意点:
由于只能抓取用户中心中的第一页数据,所以时间的选择上,最好选择上一周时间内。而且excel表格生成时,要把excel关了,不然会导致生成excel表不成功。
代码已放在github中,欢迎使用(希望简书不会把我拉黑): 前往github.
对了,这个爬虫的名字叫做: 大黄蜂
